Haben Sie sich jemals gefragt, ob Sie so etwas wie ChatGPT lokal auf Ihrem Mac ausführen könnten, ohne das Internet zu benötigen? Mit nur ein wenig Einrichtung ist das tatsächlich möglich. Auch das kostenlos. Ganz gleich, ob Sie Ihre Chats privat halten oder einfach nur offline auf KI zugreifen möchten: Hier erfahren Sie, wie Sie leistungsstarke, große Sprachmodelle lokal auf Ihrem Mac ausführen können.
#image_title
Was benötigen Sie, um ein LLM lokal auf einem Mac auszuführen?
Bevor wir loslegen und uns das Setup ansehen, benötigen Sie Folgendes:
Wir werden ein kostenloses Tool namens verwendenZu sein, mit dem Sie LLMs mit nur wenigen Befehlen herunterladen und lokal ausführen können. So fangen Sie an:
Siehe auch:So führen Sie den Datei-Explorer als Administrator in Windows 11 aus
Schritt 1: Homebrew installieren (überspringen, falls bereits installiert)
Homebrew ist ein Paketmanager für macOS, der Ihnen bei der Installation von Apps über die Terminal-App hilft. Wenn Sie Homebrew bereits auf Ihrem Mac installiert haben, können Sie diesen Schritt überspringen. Wenn Sie dies jedoch nicht tun, können Sie es wie folgt installieren:
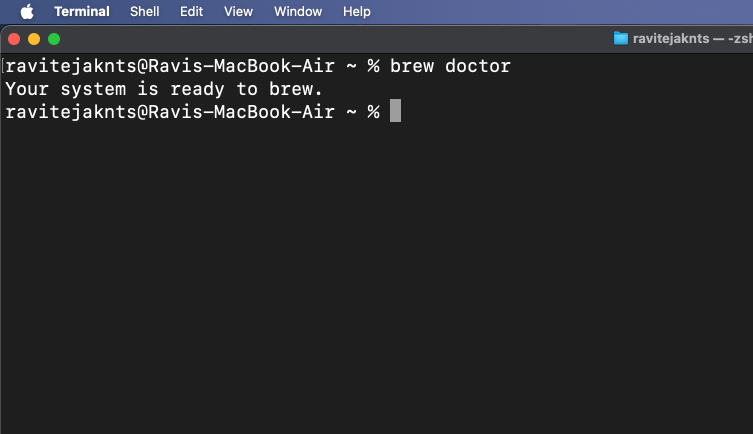
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"brew doctor
Wenn Sie die Meldung „Ihr System ist bereit zum Brühen“ sehen, können Sie loslegen.
Wenn Sie Probleme haben oder eine detailliertere Schritt-für-Schritt-Anleitung wünschen, lesen Sie unsere Anleitung zur Installation von Homebrew auf einem Mac.
Schritt 2: Ollama installieren und ausführen
Nachdem Homebrew nun auf Ihrem Mac installiert und einsatzbereit ist, installieren wir Ollama:
brew install ollamaollama serve
Lassen Sie dieses Fenster geöffnet oder minimieren Sie es. Dieser Befehl sorgt dafür, dass Ollama im Hintergrund läuft.
Alternativ können Sie auch die herunterladenOllama-Appund installieren Sie es wie jede normale Mac-App. Wenn Sie fertig sind, öffnen Sie die App und lassen Sie sie im Hintergrund laufen.
Schritt 3: Laden Sie ein Modell herunter und führen Sie es aus
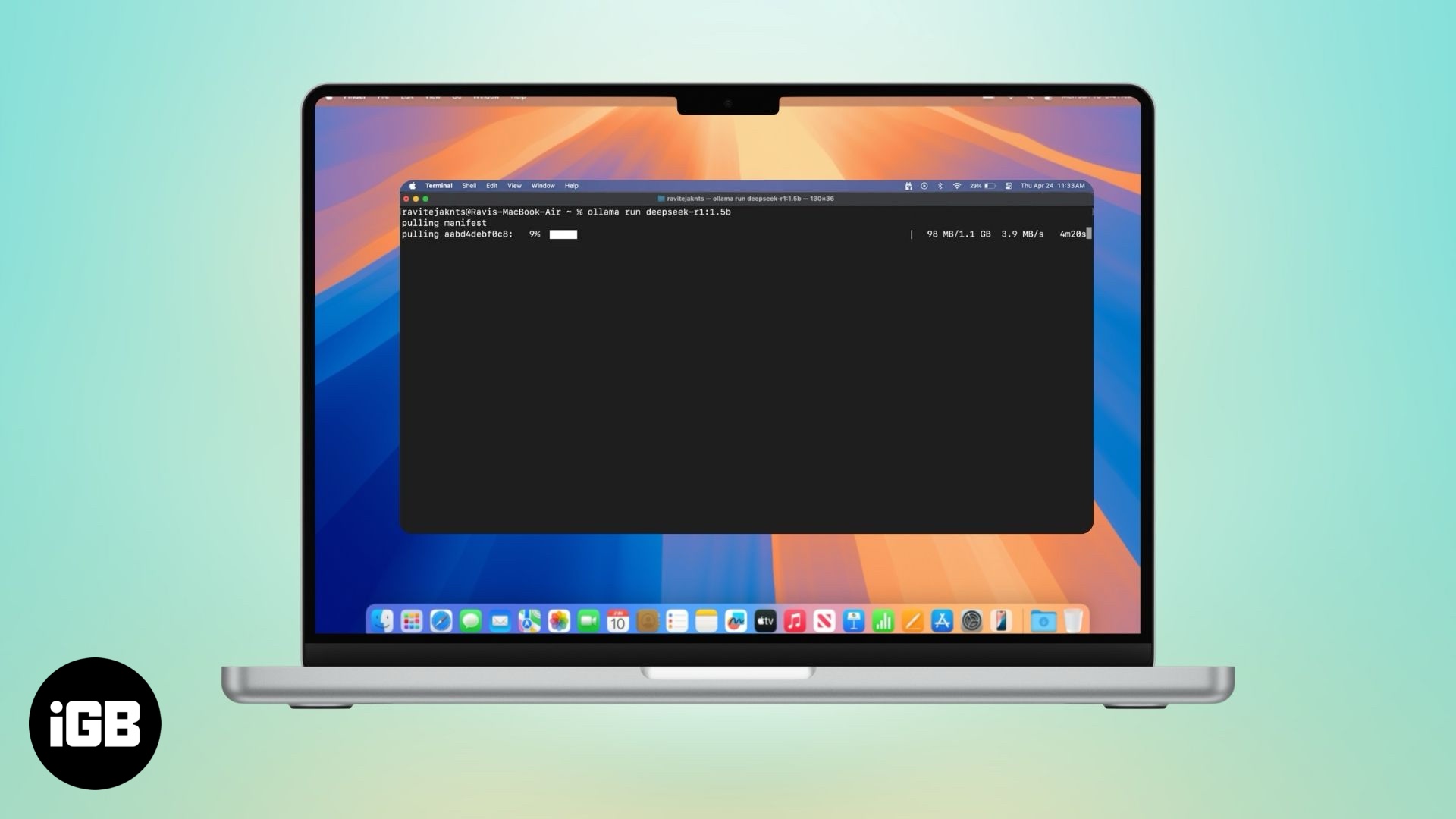
Ollama bietet Ihnen Zugriff auf beliebte LLMs wie DeepSeek, Meta’s Llama, Mistral, Gemma und mehr. So können Sie eines auswählen und ausführen:
Wenn Sie sich für ein großes Modell entscheiden, müssen Sie mit einer gewissen Verzögerung rechnen – schließlich läuft das gesamte Modell lokal auf Ihrem MacBook. Kleinere Modelle reagieren schneller, können jedoch Probleme mit der Genauigkeit haben, insbesondere bei mathematischen und logikbezogenen Aufgaben. Bedenken Sie außerdem, dass diese Modelle keine Echtzeitinformationen abrufen können, da sie keinen Internetzugang haben.
Allerdings funktionieren sie hervorragend, wenn es um Dinge wie das Überprüfen der Grammatik, das Schreiben von E-Mails oder das Brainstorming von Ideen geht. Ich habe DeepSeek-R1 ausgiebig auf meinem MacBook mit einem Web-UI-Setup verwendet, mit dem ich auch Bilder hochladen und Codeausschnitte einfügen kann. Auch wenn seine Antworten – und vor allem seine Programmierfähigkeiten – nicht so scharf sind wie bei Spitzenmodellen wie ChatGPT oder DeepSeek 671B, erledigt es dennoch die meisten alltäglichen Aufgaben, ohne dass das Internet erforderlich ist.
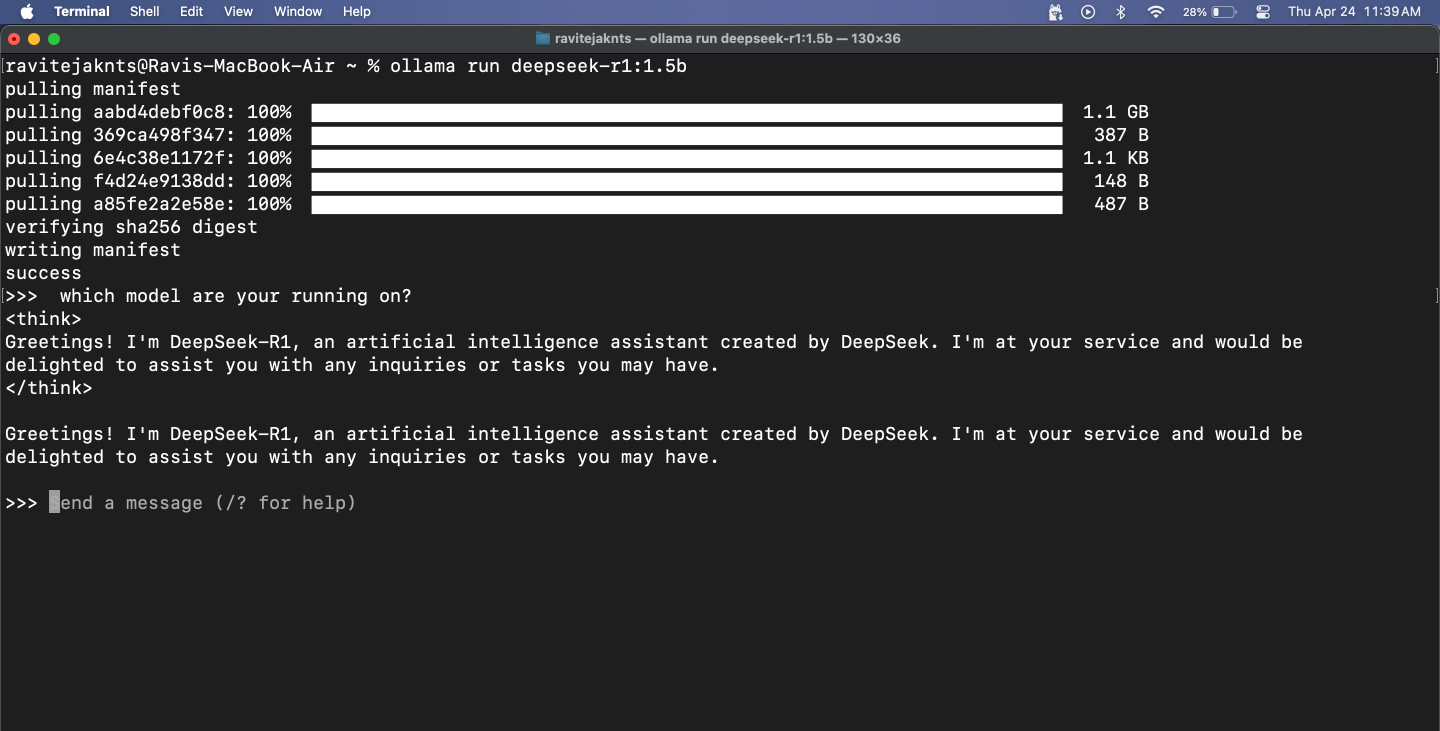
Schritt 4: Chatten Sie mit dem Modell im Terminal
Sobald das Modell läuft, können Sie einfach Ihre Nachricht eingeben und drückenZurückkehren. Das Modell wird direkt unten antworten.
Um die Sitzung zu verlassen, drücken SieStrg+Dauf Ihrer Tastatur. Wenn Sie wieder mit dem Chatten beginnen möchten, verwenden Sie einfach dasselbeollama run [model-name]Befehl. Da das Modell bereits heruntergeladen ist, wird es sofort gestartet.
Schritt 5: Installierte Modelle anzeigen und verwalten
Führen Sie Folgendes aus, um zu überprüfen, welche Modelle derzeit heruntergeladen werden:
ollama list

Um ein Modell zu löschen, das Sie nicht mehr benötigen, verwenden Sie:
ollama rm [model-name]Bonus: Nutzen Sie Ollama mit einer Benutzeroberfläche im Web
Während Ollama im Terminal ausgeführt wird, startet es auch einen lokalen API-Dienst unter https://localhost:11434, sodass Sie es mit einer Weboberfläche für die visuelle Interaktion mit den Modellen verbinden können – ähnlich wie bei der Verwendung eines Chatbots. Eine beliebte Option hierfür ist Open WebUI, das zusätzlich zu den Kernfunktionen von Ollama eine benutzerfreundliche Oberfläche bietet. Mal sehen, wie man es einrichtet.
Schritt 1: Docker installieren
Docker ist ein Tool, mit dem Sie ein Programm und alle seine wesentlichen Elemente in einen tragbaren Container packen können, sodass Sie es problemlos auf jedem Gerät ausführen können. Wir öffnen damit eine webbasierte Chat-Oberfläche für Ihr KI-Modell.
Wenn Ihr Mac es noch nicht hat, befolgen Sie diese Schritte, um Docker zu installieren:
docker --version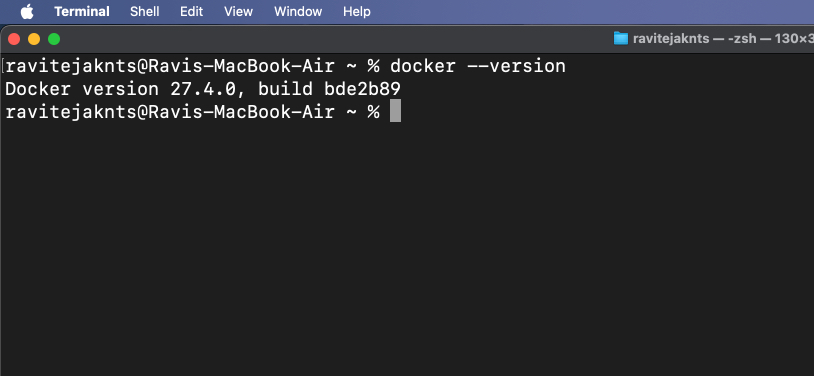
Wenn der Befehl eine Versionsnummer zurückgibt, bedeutet dies, dass Docker auf Ihrem Mac installiert ist.
Schritt 2: Rufen Sie das Open WebUI-Bild ab
Open WebUI ist ein einfaches Tool, das Ihnen ein Chat-Fenster in Ihrem Browser bietet. Das Abrufen des Bildes bedeutet lediglich, dass die zum Ausführen erforderlichen Dateien heruntergeladen werden müssen.
Gehen Sie dazu zuTerminalApp und Typ:
docker pull ghcr.io/open-webui/open-webui:mainDadurch werden die notwendigen Dateien für die Schnittstelle heruntergeladen.
Schritt 3: Führen Sie den Docker-Container aus und öffnen Sie die WebUI
Jetzt ist es an der Zeit, Open WebUI mit Docker auszuführen. Sie sehen eine übersichtliche Oberfläche, über die Sie mit Ihrer KI chatten können – kein Terminal erforderlich. Folgendes müssen Sie tun:
docker run -d -p 9783:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main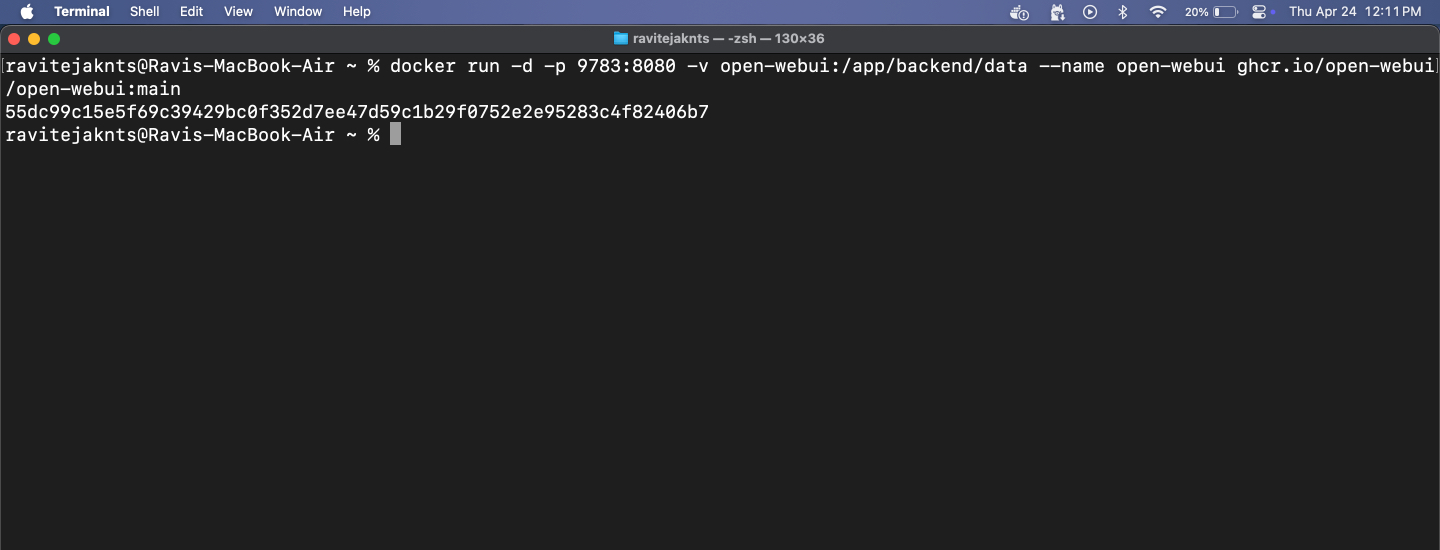
https://localhost:9783/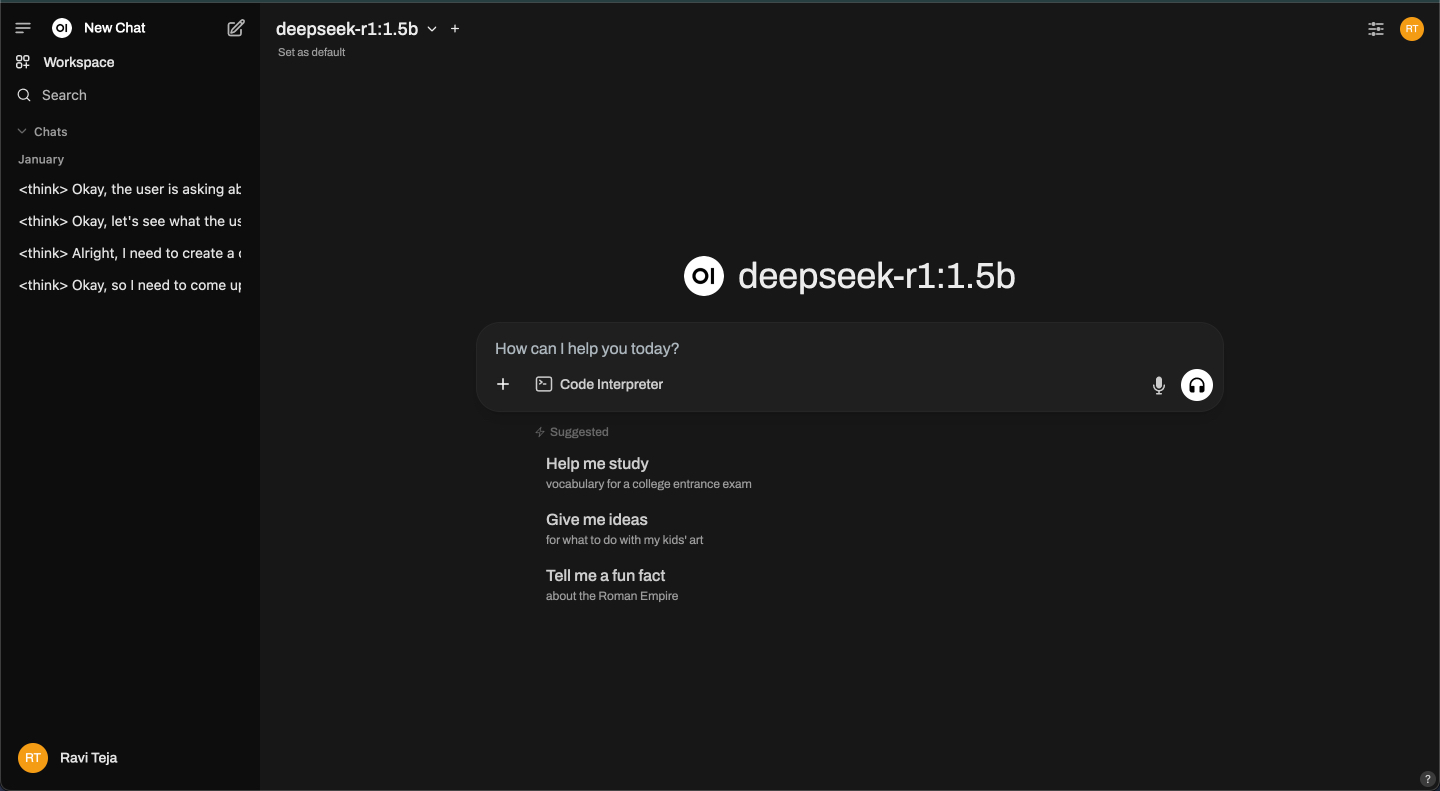
Von hier aus können Sie mit jedem installierten Modell in einer übersichtlichen, benutzerfreundlichen Browseroberfläche chatten. Dieser Schritt ist optional, ermöglicht Ihnen jedoch ein reibungsloseres Chat-Erlebnis, ohne das Terminal zu verwenden.
Ihr Mac, Ihre KI: keine Server, keine Bedingungen
Das ist es! In nur wenigen Schritten haben Sie Ihren Mac so eingerichtet, dass er ein leistungsstarkes KI-Modell vollständig offline ausführt. Nach der Einrichtung sind keine Konten, keine Cloud und kein Internet erforderlich. Egal, ob Sie private Gespräche führen, lokalen Text generieren oder einfach nur mit LLMs experimentieren möchten, Ollama macht es einfach und zugänglich – auch wenn Sie kein Entwickler sind. Probieren Sie es aus!
Schauen Sie sich auch diese hilfreichen Leitfäden an: