Apple heeft SlowFast-LLaVA-1.5 geïntroduceerd, een nieuwe familie video-grote taalmodellen (Video-LLM's) die zijn ontworpen om lange video efficiënt te begrijpen. In zijn onderzoekspaper legt Apple uit dat de meeste bestaande video-LLM's worstelen met hoge rekenkosten en overmatig tokengebruik bij het analyseren van uitgebreide video-inhoud, wat hun vermogen om te schalen beperkt. SlowFast-LLaVA-1.5 pakt dit aan door een token-efficiënt raamwerk te introduceren dat het aantal tokens vermindert dat nodig is om video weer te geven, terwijl de nauwkeurigheid behouden blijft.
Token-efficiëntie is van cruciaal belang omdat elk frame in een video moet worden omgezet in tokens voordat een LLM het kan verwerken. Met lange video wordt het aantal tokens snel onbeheersbaar, waardoor de kosten stijgen en de prestaties afnemen. De aanpak van Apple comprimeert videogegevens zodat er minder tokens worden gebruikt zonder dat belangrijke context verloren gaat. Door dit te combineren met een dual-pathway-architectuur, waarbij een “langzaam” pad langetermijnpatronen vastlegt en een “snel” pad zich richt op kortetermijndetails, kan het model begrip in evenwicht brengen met efficiëntie. Hierdoor kan het zowel overkoepelende verhaallijnen als fijnmazige acties over uitgebreide reeksen volgen.
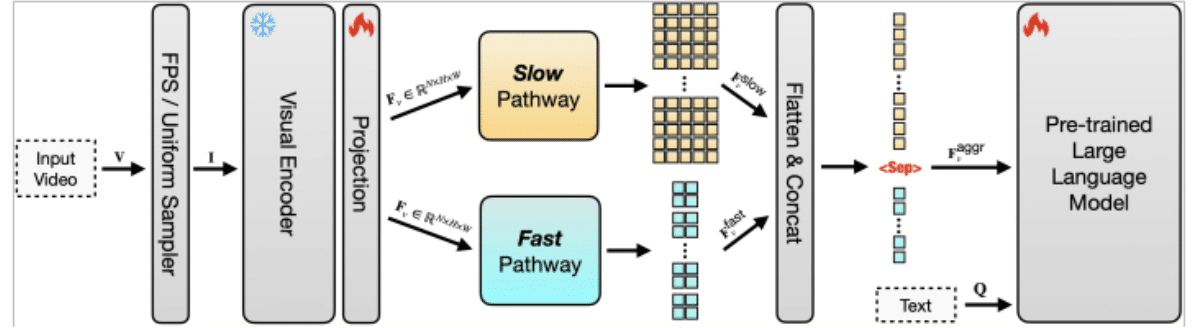
Het systeem is ook zeer schaalbaar, wat betekent dat het kan worden uitgebreid om veel langere video's en grotere datasets te verwerken zonder overweldigende computerbronnen. Traditionele modellen worden onpraktisch naarmate de invoerlengte toeneemt, maar het ontwerp van Apple zorgt ervoor dat opschalen van korte clips naar beeldmateriaal van meerdere uren haalbaar blijft. Dit maakt SlowFast-LLaVA-1.5 geschikt voor taken zoals het beantwoorden van videovragen, temporeel redeneren, samenvatten en het ophalen van inhoud in lange video-archieven.
In benchmarktests meldt Apple dat het model sterke resultaten behaalt op datasets als Video-MME en LongVideoBench, wat zowel een verbeterde efficiëntie als een beter begrip laat zien vergeleken met eerdere benaderingen. Het onderzoek introduceert ook meerdere modelgroottes, waaronder 1,5B-, 7B- en 13B-parameterversies, die op instructies zijn afgestemd om aanwijzingen in natuurlijke taal te volgen. Hierdoor kan het systeem gedetailleerde antwoorden genereren over complexe video-inhoud, waardoor het toepasbaar wordt voor educatieve videoanalyse, samenvattingen van vergaderingen en toegankelijkheidstools die ondertitels of doorzoekbare transcripties creëren.
Lees meer:TikTok omarmt lange inhoud met video-uploads van 60 minuten
Apple benadrukt dat het token-efficiënte en schaalbare ontwerp niet alleen gaat over nieuwigheden in onderzoek, maar ook over praktische aspecten. Door de computervereisten te verlagen en tegelijkertijd de mogelijkheden uit te breiden, maakt het model de weg vrij voor het integreren van lange-vorm video-inzicht in producten uit de echte wereld. Nu video de dominante rol blijft spelen op het gebied van entertainment, onderwijs en professionele communicatie, vertegenwoordigt de lange video-LLM van Apple een belangrijke stap in de richting van het zowel bruikbaar als toegankelijk maken van geavanceerde multimodale AI.
Bekijk het volledige documenthier.