Apple har introduceret SlowFast-LLaVA-1.5, en ny familie af video-store sprogmodeller (Video-LLM'er), der er designet til effektivt at forstå langformat video. I sit forskningspapir forklarer Apple, at de fleste eksisterende video LLM'er kæmper med høje beregningsomkostninger og overdreven token-brug, når de analyserer udvidet videoindhold, hvilket begrænser deres evne til at skalere. SlowFast-LLaVA-1.5 løser dette ved at introducere en token-effektiv ramme, der reducerer antallet af tokens, der er nødvendige for at repræsentere video, samtidig med at nøjagtigheden bevares.
Tokeneffektivitet er kritisk, fordi hver frame i en video skal konverteres til tokens, før en LLM kan behandle den. Med video i lang format bliver antallet af tokens hurtigt uoverskueligt, hvilket øger omkostningerne og sænker ydeevnen. Apples tilgang komprimerer videodata, så der bruges færre tokens uden at miste vigtig kontekst. Ved at kombinere dette med en dual-pathway-arkitektur, hvor en "langsom" pathway fanger langsigtede mønstre og en "hurtig" pathway fokuserer på kortsigtede detaljer, kan modellen balancere forståelse med effektivitet. Dette gør det muligt at spore både overordnede historielinjer og finkornede handlinger på tværs af udvidede sekvenser.
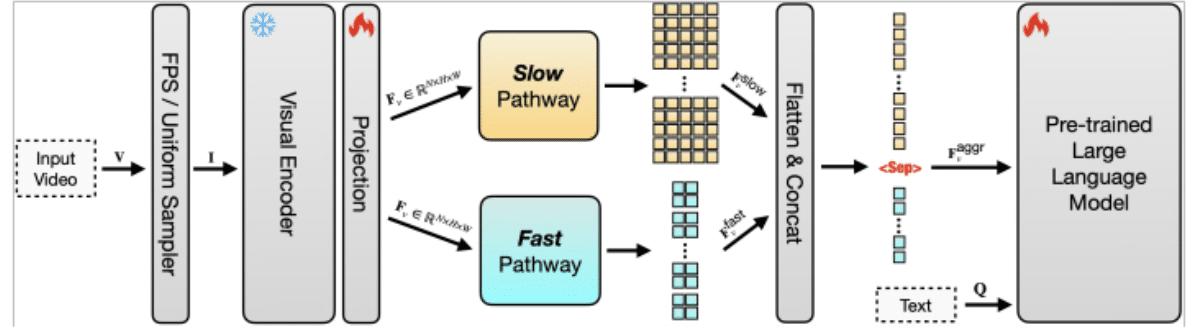
Systemet er også meget skalerbart, hvilket betyder, at det kan udvides til at håndtere meget længere videoer og større datasæt uden overvældende computerressourcer. Traditionelle modeller bliver upraktiske, efterhånden som inputlængden øges, men Apples design sikrer, at skalering fra korte klip til multi-timers optagelser forbliver mulig. Dette gør SlowFast-LLaVA-1.5 velegnet til opgaver såsom besvarelse af videospørgsmål, tidsmæssig ræsonnement, opsummering og indholdshentning på tværs af lange videoarkiver.
I benchmark-tests rapporterer Apple, at modellen opnår stærke resultater på datasæt som Video-MME og LongVideoBench, hvilket viser både forbedret effektivitet og forståelse sammenlignet med tidligere tilgange. Forskningen introducerer også flere modelstørrelser, inklusive 1,5B, 7B og 13B parameterversioner, som er instruktionsjusteret til at følge prompter fra naturligt sprog. Dette giver systemet mulighed for at generere detaljerede svar om komplekst videoindhold, hvilket gør det anvendeligt til undervisningsvideoanalyse, mødeopsummering og tilgængelighedsværktøjer, der skaber billedtekster eller søgbare transskriptioner.
Læs mere:TikTok omfavner indhold i lang form med 60 minutters videoupload
Apple understreger, at det token-effektive og skalerbare design ikke kun handler om forskningsnyhed, men om praktisk. Ved at sænke beregningskravene samtidig med at kapaciteten udvides, baner modellen vejen for at integrere langform videoforståelse i produkter fra den virkelige verden. Da video fortsætter med at dominere inden for underholdning, uddannelse og professionel kommunikation, repræsenterer Apples langformede video LLM et væsentligt skridt hen imod at gøre avanceret multimodal AI både anvendelig og tilgængelig.
Tjek hele avisenher.